
우리도 이제 AI 에이전트 필요함!
ChatGPT처럼 하면 돼?
회사에서 AI 데이터 분석 에이전트의 프론트엔드를 맡게 됐습니다. 처음엔 단순하게 생각했어요. "ChatGPT처럼 스트리밍으로 텍스트 뿌려주면 되는 거 아닌가?"
근데 기획서를 보니 전혀 달랐습니다. 응답이 단순 텍스트가 아니었어요.
- 핵심 지표는 카드 UI로 보여줘야 하고
- 중간에 차트가 끼어들어야 하고
- 분석 조건은 태그 형태로 표시해야 하고
- 인사이트는 리스트 UI로 구조화해야 하고
- 이 모든 게 스트리밍 중에 실시간으로 나타나야 했습니다
마크다운 스트리밍으로는 절대 안 되는 구조였어요.
왜 XML이었는가
응답 포맷을 뭘로 할지가 첫 번째 판단이었습니다.
마크다운 — 가장 흔한 선택이지만, 구조화된 UI 블록을 표현할 수 없습니다. 이 부분은 차트로 렌더링해라는 의미를 마크다운으로 전달할 방법이 없어요.
JSON — 구조 표현은 가능하지만, 스트리밍 중 파싱이 불가능합니다. 닫는 }가 아직 안 왔으면 중간 상태를 파싱할 수 없어요. partial JSON parser 같은 것도 있지만 불안정합니다.
XML — 여는 태그가 도착하는 순간 이 블록이 시작됐다를 알 수 있습니다. 중첩 구조도 자연스럽고, LLM이 XML 생성을 잘 합니다. 그리고 결정적으로 — htmlparser2가 이미 청크 단위 스트리밍 파싱을 지원합니다.
<!-- 서버에서 이런 형태로 스트리밍됨 -->
<main-title>최근 7일 매출 분석</main-title>
<core-indicator value="1,234,567" label=총 매출 trend="+12%" />
<query-condition>기간: 5/13~5/20, 필터: 모바일, 그룹: 일별</query-condition>
<ai-visualization id="chart-abc123" />
<insight-discovery>
<insight-list>
<insight-item>수요일 매출이 전주 대비 23% 상승</insight-item>
<insight-item>신규 유저 비중이 41%로 역대 최고</insight-item>
</insight-list>
</insight-discovery>
각 태그가 곧 Vue 컴포넌트와 1:1 매핑됩니다. <core-indicator>는 카드 컴포넌트로, <ai-visualization>은 차트 컴포넌트로, <insight-item>은 리스트 아이템으로. 포맷 자체가 UI 설계서인 셈이죠.
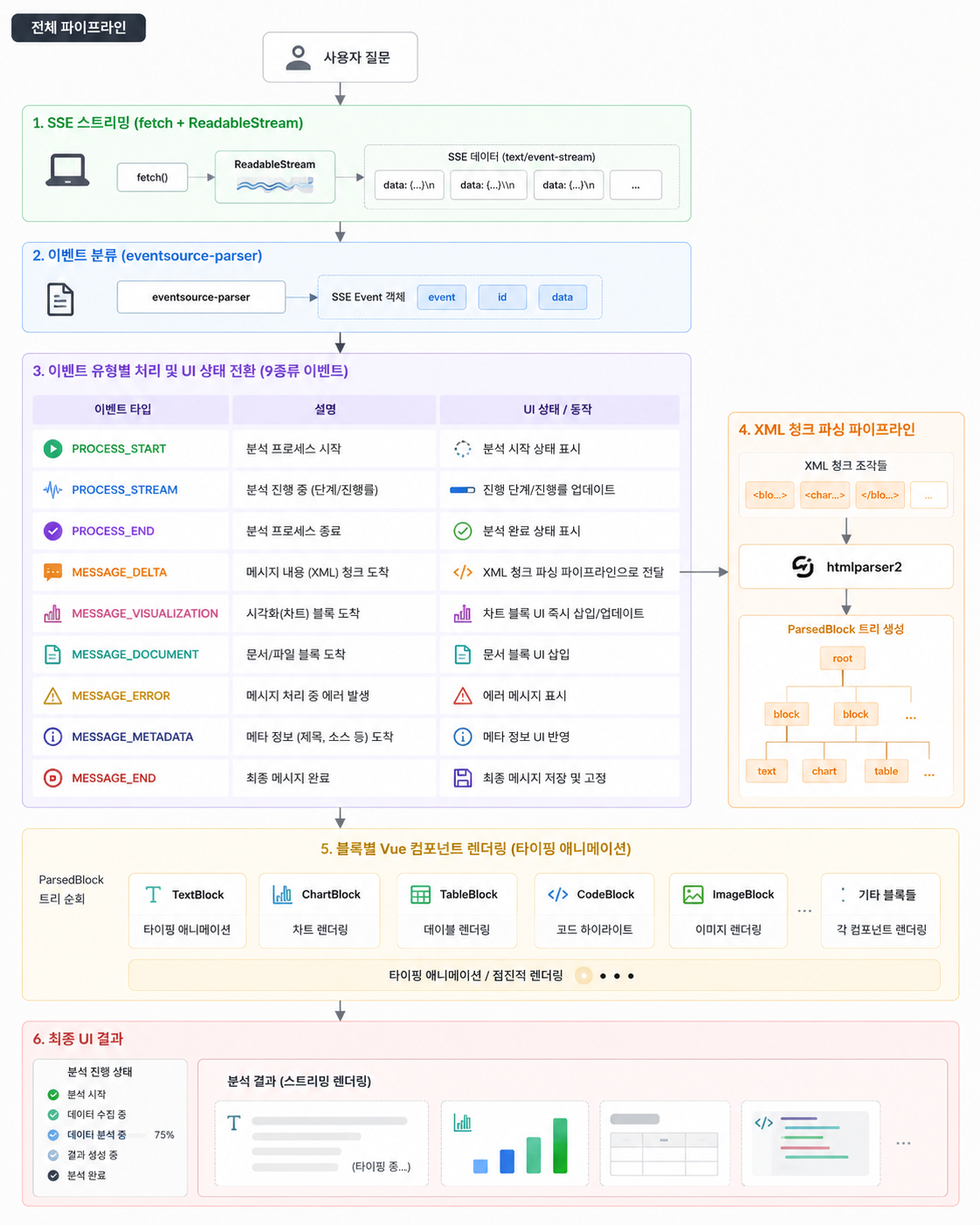
전체 파이프라인
(오. 이번에도 열일한 GPT 5.5 의 실력.!)
단순히 텍스트를 뿌리는 게 아니라, 9종류의 SSE 이벤트를 구분해서 각각 다른 UI 상태로 전환해야 했습니다.
SSE 스트리밍: EventSource를 안 쓴 이유
브라우저 내장 EventSource가 있는데 왜 직접 구현했냐면:
EventSource는 GET만 지원 — 우리는 POST로 대화 컨텍스트를 보내야 함- 헤더 커스터마이징 불가 — 인증 토큰을 넣을 수 없음
- 타임아웃 제어 불가 — 분석이 10분까지 걸릴 수 있음
그래서 fetch + ReadableStream + eventsource-parser 조합으로 갔습니다.
const response = await fetch(url, {
method: 'POST',
body: JSON.stringify(requestModel),
headers: { Authorization: `Bearer ${token}` },
});
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
const parser = createParser({ onEvent: handleSSEEvent });
while (true) {
const { value, done } = await reader.read();
if (done) break;
parser.feed(decoder.decode(value, { stream: true }));
}
eventsource-parser가 SSE 프로토콜(event/data/id 필드)을 파싱해주니까, 우리는 이벤트 타입별 핸들러만 작성하면 됩니다.
XML 스트림 파싱: 청크가 태그 중간에서 잘리면?
SSE의 MESSAGE_DELTA 이벤트로 XML 조각이 날아옵니다. 문제는 — 네트워크 청크가 태그 중간에서 잘릴 수 있다는 거예요.
청크 1: "<insight-disc"
청크 2: "overy><insight-list><insight-it"
청크 3: "em>전주 대비 12% 상승</insight-item>"
htmlparser2가 이걸 처리해줍니다. parser.write(chunk)를 호출하면 내부적으로 버퍼링하면서 완성된 태그만 콜백을 발생시켜요.
const parser = new htmlparser2.Parser({
onopentag(name, attribs) {
// 새 블록 시작 → ParsedBlock 생성, 트리에 추가
const newBlock = { type: name, content: '', attributes: attribs, children: [] };
// 부모-자식 관계에 따라 트리 구성
},
ontext(text) {
// 텍스트 도착 → 현재 블록에 추가 + 타이핑 애니메이션 큐잉
},
onclosetag(name) {
// 블록 종료 → 스택에서 pop
},
});
부모-자식 관계를 미리 정의해두는 것이었습니다. insight-discovery는 insight-list를 자식으로 가질 수 있고, insight-list는 insight-item을 가질 수 있고. 이 맵이 없으면 모든 태그가 플랫하게 나열돼서 구조를 잃어버려요.
const parentChildMap = {
'insight-discovery': ['insight-list', 'text'],
'insight-list': ['insight-item'],
'data-pattern-analysis': ['pattern-list', 'text'],
'pattern-list': ['pattern-item'],
};
타이핑 애니메이션: 스트림 속도 ≠ 렌더링 속도
서버에서 청크가 불규칙하게 옵니다. 어떤 때는 한꺼번에 200자가 오고, 어떤 때는 0.5초 동안 아무것도 안 오고. 이걸 그대로 화면에 뿌리면 뚝뚝 끊기는 느낌이 납니다.
requestAnimationFrame 기반 TextAnimator를 만들었습니다. 도착한 텍스트를 큐에 넣고, 프레임마다 N글자씩 꺼내서 렌더링합니다.
class TextAnimator {
private animationQueue: { text: string; callback: Function }[] = [];
private charsPerFrame = 3;
addText(text: string, callback: (chunk: string) => void) {
this.animationQueue.push({ text, callback });
this.startIfNeeded();
}
private animateFrame() {
// 프레임당 charsPerFrame 글자만 꺼내서 콜백 호출
// 큐가 빌 때까지 반복
}
}
이렇게 하면:
- 서버에서 한꺼번에 많이 와도 → 일정 속도로 부드럽게 출력
- 서버가 잠깐 멈춰도 → 큐에 남은 텍스트가 계속 흘러나옴
체감 속도가 균일해집니다. ChatGPT가 부드럽게 느껴지는 것도 같은 원리입니다.
차트가 스트림 중간에 끼어드는 문제
텍스트만 스트리밍되면 단순한데, 중간에 차트가 끼어듭니다. 서버가 SQL을 실행하고 결과를 집계한 뒤, MESSAGE_VISUALIZATION 이벤트로 차트 데이터를 보내요.
MESSAGE_DELTA: "<main-title>매출 분석</main-title><core-indicator..."
MESSAGE_DELTA: "...value='1234' />"
MESSAGE_VISUALIZATION: { id: "chart-1", type: "line", data: [...] }
MESSAGE_DELTA: "<insight-discovery>..."
차트 이벤트가 오면 현재 파싱 중인 XML 블록 리스트에 차트 블록을 직접 삽입합니다. XML 파서와는 별개 경로로 들어오는 거예요.
case 'MESSAGE_VISUALIZATION':
const chartBlock = convertToChartModel(parsedData);
parsedBlocks.value.push(chartBlock); // XML 블록 리스트에 직접 삽입
break;
렌더링 쪽에서는 블록 타입을 보고 분기합니다:
<template v-for="block in parsedBlocks">
<CoreIndicatorCard v-if="block.type === 'core-indicator'" :data="block" />
<ChartVisualization v-else-if="block.type === 'ai-visualization'" :data="block" />
<InsightDiscovery v-else-if="block.type === 'insight-discovery'" :data="block" />
<BodyText v-else-if="block.type === 'text'" :content="block.content" />
</template>
복합 질문 분해: "분석 중..." 이 그냥 로딩이 아닌 이유
지난달 대비 이번달 매출 변화를 채널별로 보여주고, 이탈률도 같이 분석해줘
이런 질문은 서버가 여러 sub-question으로 쪼갭니다. 프론트에서는 각 단계의 진행 상태를 실시간으로 보여줘야 했어요.
PROCESS_START: { splitQuestions: [채널별 매출 변화, 이탈률 분석], jobId: "..." }
PROCESS_STREAM: { step: "query_1", data: "SQL 생성 중..." }
PROCESS_DATA: { step: "query_1", data: true } // 완료
PROCESS_STREAM: { step: "query_2", data: "데이터 집계 중..." }
PROCESS_END: {}
MESSAGE_START: {}
MESSAGE_DELTA: "<main-title>..."
PROCESS_* 이벤트들은 "분석 진행 UI"를 제어하고, MESSAGE_* 이벤트들은 응답 렌더링을 제어합니다. 두 단계가 시간적으로 분리돼 있어서, 사용자가 지금 뭘 하고 있는지 알 수 있습니다. 그냥 스피너 돌리는 것보다 체감 대기 시간이 훨씬 짧아요.
취소 처리는 어떻게?
사용자가 분석 중에 "취소"를 누르면? 두 가지를 동시에 해야 합니다:
- 클라이언트: ReadableStream 읽기 중단 + 파서 리셋 + UI 상태 초기화
- 서버: 진행 중인 분석 job 취소 API 호출
클라이언트만 끊으면 서버는 계속 분석을 돌리고 있어요. 토큰 비용이 계속 나갑니다. 그래서 취소 시 별도 API를 호출해서 서버 job도 중단시킵니다.
돌이켜보면
좋았던 점: XML + 스트리밍 파싱 조합이 잘 동작했습니다. 새로운 블록 타입을 추가할 때 태그 하나 + 컴포넌트 하나만 만들면 되니까 확장도 쉬웠어요. 타이핑 애니메이션도 UX를 확실히 개선했고요.
아쉬웠던 점: 태그가 18종까지 늘어나면서 관리가 복잡해졌습니다. 서버 LLM 프롬프트에도 태그 스펙을 전부 명시해야 하는데, 프론트에서 태그를 추가하면 백엔드 프롬프트도 같이 수정해야 해서 배포 의존성이 생겼어요.
다시 한다면: 태그 종류를 줄이고, 속성(attribute)으로 변형을 표현했을 겁니다. <insight-item>과 <pattern-item>을 따로 만들 게 아니라 <list-item type="insight"> 같은 식으로요. 그리고 태그 스펙을 프론트/백엔드가 공유하는 스키마 파일로 관리했을 겁니다.